In case of a graphical user interface, the user many times starts shorter-longer operations by some GUI elements, like pressing a button. We mentioned in the previous post that these operations should be started on a separate thread to avoid freezing the GUI or to avoid dealing with user interface handling (calling Application.DoEvents()) from those operations. It also happens that these operations can be divided into more sub-operations, and these sub-operations could be executed in parallel.
In case of calculation heavy tasks, on an old single core CPU, these tasks can be executed one by one, and it gives better performance than executing them parallel/time sharing. In case of a multi core CPU, or if tasks do I/O operations, the operations can be executed in parallel using different threads for better performance.
The Price of a Thread
Unfortunately, handling threads as resources is not trivial. Starting a new thread is expensive in term of time and memory. The figure below shows as a program starts 100 threads, which threads do nothing just wait. Green is the number of threads, blue is the memory consumption.
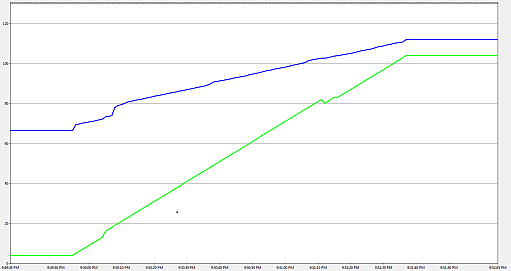
Although the threads do nothing, so they don’t allocate any memory for effective work, the memory consumption of the program increased by more than 50%. Besides the memory consumption, the execution speed is also a concern. A modern CPU is able to count up to 100000 within a fraction of a millisecond. Let’s implement this calculation in a way where every individual increment happens on a new thread (the result will be more than 100000 due to the lack of proper synchronization):
Stopwatch sw = Stopwatch.StartNew();
var counter = 0;
while (Volatile.Read(ref counter) < 100000)
{
new Thread(
() => Interlocked.Increment(ref counter)
).Start();
}
Console.WriteLine("{0} - {1}", sw.ElapsedMilliseconds, counter);
The result on a two core CPU is 14 seconds, which is very slow considering the simple task. This time is almost exclusively consumed by starting new threads and controlling them.
Reusing threads
A good idea for a better solution is that if a thread has been already started by the operating system, then that thread could be used to execute other tasks, too, not only one. In this case the cost of the time and memory spent on creating a thread will be distributed among multiple tasks, resulting a better average performance. Of course, a single thread is able to execute only one task at a time, so multiple tasks can only be executed one after the other. But as we have seen, if the number of tasks to be executed is much more than the number of cores in the CPU, the sequential execution gives better performance – at least for computing oriented tasks.
Thread Pools are based on the idea of reusing already existing threads. In a Thread Pool, some pre-created threads wait for tasks to be executed. Thread Pools generally have a queue in which tasks can be put. The threads waiting then grab tasks from the queue and execute them. In this way the cost of creating a thread will not be added to every single task.
Thread pools are not only about some threads waiting for tasks, though. It is hard to find a good algorithm to decide how many threads should be waiting or when to create additional threads. If a thread pool has only a few threads, and all of these threads are working on tasks with lot of I/O operations, it can happen that tasks are waiting in the queue, the CPU is not utilized and no threads will take new tasks. If there are too many threads, and all the tasks are about calculations, the CPU starts time sharing which decreases the average executing time of the tasks. It is not obvious to find a good balance.
The Windows operating system implements a Thread Pool, but the .Net framework doesn’t use it. .Net implements its own Thread Pool. The algorithm behind this Thread Pool changes by .Net versions. In the first versions a simple algorithm started with a minimum number of threads, and when tasks were waiting for too long time in the queue, then the Thread Pool started new and new threads. This algorithm worked well if the threads started operations with lots of I/O. But if threads were just calculating, the more threads forced the CPU intensive time sharing which made the performance worse. Later the thread pool monitored the CPU load before started new threads. .NET 4 used a sophisticated “hill climbing” algorithm which tried to find the optimal number of threads. In case of heavy load, this algorithm started to increase the number of threads, until the throughput started decreasing. When it happened, the thread pool lowered the number of threads. So it maintained a performance curve and tried to stay on the top.
Now, we can try the multithreaded counting example using the Thread Pool. The following program – without further explanation – places a task on the thread pool for every single increment, so the Thread Pool must process around 100000 tasks (the result will be more due to the lack of proper synchronization).
var sw = Stopwatch.StartNew();
var counter = 0;
while (Volatile.Read(ref counter) < 100000)
{
ThreadPool.UnsafeQueueUserWorkItem(
_ => Interlocked.Increment(ref counter),
null);
}
Console.WriteLine("{0} - {1}", sw.ElapsedMilliseconds, counter);
The execution time is approximately 15ms on a quite old 2 core CPU, so this solution is almost 1000 times faster than starting a new thread for every increment. Remember that this is an edge case and it would be a wrong conclusion saying that the Thread Pool is 1000 times faster in general. But we can say that the performance hit of creating threads can be minimalized, and an optimal load of the CPU can be maintained using Thread Pool.
In the next part we will see how Windows handle slow devices and how Completion Ports work – which is an importan building block of the .Net Thread Pool
