Writing multithreaded applications has been an option for a while in Windows. It was possible even under Windows 95. It is easy to answer that why it became a hot topic to write multithreaded programs in the last couple of years. Newer generation microprocessors are built with multiple cores, so they are able to execute more threads in parallel. But what was the benefit of writing multithreaded applications 20 years ago for single core processors?
Sharing CPU time: is it worth it?
Many operating systems uses the following strategy to run multiple threads: a given thread gets a certain amount of time, so that it can use the processor to do some work. Then the operating system freezes that thread, stores its execution state, like the content of the CPU registers. Then it takes a previously stored execution state of an other thread, and starts running that thread. This way the CPU starts working on a different task for a while, then the operating system selects a new thread again.
Now, if there is a single core CPU and it is about to execute four tasks in parallel, where a single task takes one minute to finish, then the result of every task will be available after four minutes. Is it really better compared to the case where the tasks run after each other? If the tasks run after each other, the result of the first task will be available after one minute – three minutes earlier than in case of parallel execution. The result of the second task will be available after two minutes, and so forth.
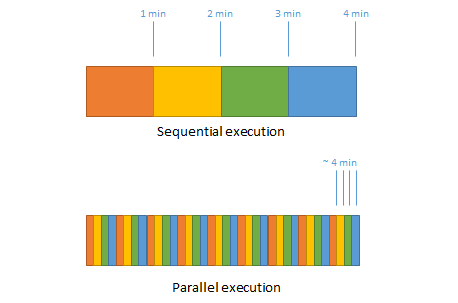
This is obvious that it doesn’t make any sense to perform those tasks in parallel, because it just results in a worse average computing time. So why did an old program on and old CPU need parallel execution?
The frozen GUI
Those who have been developing GUI applications, easily can tell a reason: if we work on a longer task on the thread that is responsible for updating the GUI, then the application will hang and will not respond to any user interaction. A funny part of this story is that when a desperate user starts the Task Manager, many times they see that the CPU does nothing.
The truth is that CPUs, at least of a client computer, usually do nothing, they just wait. The above mentioned frozen GUI application might have been waiting for the database to send back some data, other applications may be waiting for harddrive or network data, or for the user to do something. Now, the question is that if the computer does nothing, why doesn’t it deal with the user interface?
When a developer writes a program and starts it, this program mostly executes code that was not written by that developer itself. Quite often the program runs some operating system code, like file/network handling, or a 3rd party code like the client library of a database or messaging system. In these cases the developer’s code calls into the library code, which starts working, then after some period of time it gives back the control to the developer’s code. Sometimes these calls into the library code can take long time and that way the developer’s code is blocked at the point where it called into the library code.
We asked why the screen wasn’t refreshed when the computer wasn’t busy. In our example the code written by the developer doesn’t refresh the screen because the control is not in that code, so it doesn’t have a chance to do that. The database client library code, which blocks the developer’s code, will not refresh the screen because it doesn’t know that the screen is to be refreshed. It is not the concern of that code.
The situation is often the same when we don’t call a 3rd party library code, but our own code. If a developer writes a long running algorithm, then in theory they could call a method to refresh the screen for better user experience. But is this the right solution? To put a Windows Form Application.DoEvents() call into the inner loop of an algorithm? Of course not! Refreshing the screen is not the concern of an algorithm.
Logical Threads
It is much easier to write programs when we can keep the logical flow of a given task as a separate unit. An algorithm has its own logical flow and it must be separated from the logical flow of drawing a user interface. This is why developers don’t call DoEvents() from an algorithm.
What we need for handling the screen while a calculation is running, is not really the parallel execution of threads. What we need is that even when a calculation is in progress, which is a separate logical flow, the other independent flow which draws the screen should be started very soon when needed. On a single core CPU it means, that the calculation should be interrupted when the screen must be refreshed, then the screen should be drawn by the code on a different thread, then the calculation can be resumed. But how can the operating system know that when it should start the thread which draws the screen, and when it has finished its work? The operating system may know when the work is done by a special method call for example. But what happens when the GUI thread is so busy that it never calls this special method?
We have seen operating systems where logical flows decided that when they pass the CPU time to other logical flows. Windows worked this way before Windows 95 and NT. In a system like that, a long running calculation should periodically relinquish the CPU and so all the others. The problem with this solution is that not all the programs handle correctly the exclusive power of having the CPU. A small mistake is enough and a logical flow will not relinquish, which means that the whole system freezes. It happened quite often under early Windows – and we see it today in case of web applications written using javascript.
Physical Threads
To avoid this problem, newer Windows systems (where newer means the last 20 years) will take the control from a thread anyway after a certain (quite short) time. The threads do not need to relinquish, and do no need to care about other threads. On the other hand, threads are running side by side, and sharing the CPU in cases where it is not optimal, just like in the example of the four parallel calculation. If a calculation is running, the drawing of a screen might take more time because of time sharing, which might be seen by the user and make the user experience worse. Still, running threads in parallel in time sharing mode results in more stable system and simpler, clearer program logic for the developers. These are very important benefits and many times this is the motivation behind writing multithreaded applications, not the performance.
Parallel waitings
There are other reasons for parallel executions than logical separation and stability. The act of waiting for something has a nice nature. It can be parallelized without limits, because waiting for something does not requires resources. Let’s say that there are three old vending machines in the cafeteria and it takes a minute for the machines to give something, because of their old mechanics. If I have to bring soda for my two friends and for myself, I have two options. I can use one vending machine waiting for 3 minutes altogether. Or I can utilize that I am able to wait for three vending machine in the same time, so I throw in the coins for all three machines, and after a minute I collect the cans.
Time can be saved by parallelizing waitings. An average client computer runs threads in parallel in the range of 100. But most of these threads are just waiting. Waiting for data from the network, waiting for data from the hard drive or waiting for the user to press a key on the keyboard.
The way Windows handles threads is optimized for the cases we have seen above. The .NET framework uses Windows capabilities and makes some abstraction to make it more convenient for developers. The newer and newer versions of .NET provide more and more advanced techniques, so the developer can concentrate to their algorithms and logical flows instead of dealing with low level thread handling. However, in case of multithreading, not understanding what happens behind the curtains easily leads to misuse and severe performance problems.
In this multithreading series we will learn about how the operating system uses threads, and how different .Net versions give better and better tools to utilize them.
