One of the improvements we need to make on the Like Statistic application is to change the structure of the database where the datafiles are stored. The database is a directory with datafiles, and the program reads all datafiles from that given directory from a single level, but doesn’t read those from the subdirectories.
In the MainWindow class, the following method provides the files from the database to be processed. It reads the files from a single level, the first parameter is the path to the database, the second is basically the extension of the datafiles which is determined by the selected source type, like “xml” or “bin”.
private IEnumerable<string> GetFileList()
{
return FileSystem.GetFiles(
this.GetDatabasePath(),
this.GetSelectedSourceType());
}
We need to use the FileSystem class only because the .net framework Directory.GetFiles() would be able to return all files from a directory structure, and this is just too easy, we wanted the candidates working a little-bit more, so they need to find an algorithm which walks through the directory structure. The FileSystem class is a simple wrapper around the .Net framework Diretory class:
internal static class FileSystem
{
internal static string[] GetFiles(string path, string extension)
{
return Directory.GetFiles(path, "*." + extension);
}
internal static string[] GetDirectories(string path)
{
return Directory.GetDirectories(path);
}
}
We can use two simple methods from the FileSystem class, the first returns all files from a given path, and the second returns all directories from a given path.
What is recursion?
We have a directory structure, its a tree structure, and many candidates can recall that if we want to walk through a tree structure, we can use recursion. But when I ask about what recursion is, the most common answer is that its when a method calls itself.
This answer is kind of ok, but there is a better way to think about recursion. The fact that a method calls itself is just a result of a problem solving strategy. When we think about recursion, it should be just a special way we solve the problem, not a way we call a method.
What is this strategy? From time to time we see problems that when we start to solve, they fall apart to more sub-problems which have the same shape than the original problem. Sometimes this happens without any effort, sometimes we need to be tricky to make the sub-problems to have the same shape.
Let’s see an example. This example is simple, still many developers have problems solving it on an interview, probably because we can solve this problem more easily without recursion. Let’s say, that we have an array:
int[] a = { 4, 6, 7, 5, 8, 2, 8 };
Now we need to write a program that increases every element in the array by one. It is simple, we just write a loop:
for (var i = 0; i < a.Length; i++) a[i]++;
Let’s say, that we are using a buggy c# compiler, and it cannot compile anything that is related to loops. We don’t have ‘for’, ‘while’, but we cannot trick it using ‘goto’. What we can do is to increment a given element like a[0] or a[10]:
static void Increment(int[] a)
{
if (a.Length > 0)
a[0]++;
else
return;
if (a.Length > 1)
a[1]++;
else
return;
...
if (a.Length > 2345643)
a[2345643]++;
else
return;
...
}
This solution has two main problems. First, it can be really long, second, we never know what the largest array is we need to be able to handle, so we don’t know what should be the last number we try.
Let’s just solve a part of the problem. The original problem is that we want to increase [a1,…,an]. First, we just solve it for [a1]
if (a.Length > 0) a[0]++;
The remaining problem is to increase [a2,…,an], which is quite similar to the original problem, but smaller. How can we use this?
Let’s write the original problem a little more general way.
Given [a1,…,ak,…,an].
Our task is to increment [ak,…,an].
If k=1, then we get the original problem, which is to increment every element in the array.
Let’s solve a part of the problem, increment only ak from [ak,…,an]
static void Increment(int[] a, int k)
{
a[k]++;
}
The remaining problem is to increment items [ak+1,…,an], which is smaller than the original problem but has exactly the same shape. Because it has exactly the same shape, we can use the method we are currently writing to solve it. That is the point of the recursion. We try to find or make sub-problems that are the same as the problem we are currently solving, because in that case we can use the currently written method to solve them. So let’s do this:
static void Increment(int[] a, int k)
{
a[k]++;
Increment(a, k+1);
}
We are almost done, we need to take care of one little thing, as the original problem becomes smaller and smaller, there is a point when it disappears, and we don’t catch that point in the current code, in our case the value of ‘k’ can grow too high. We need to stop when we reach the end of the array, so the final code looks like this:
static void Increment(int[] a, int k)
{
a[k]++;
if (k+1 < a.Length)
Increment(a, k+1);
}
Now that we have seen how it is important to understand how a problem can be divided into similar sub-problems, lets work with the directory structure. Our problem is the following:
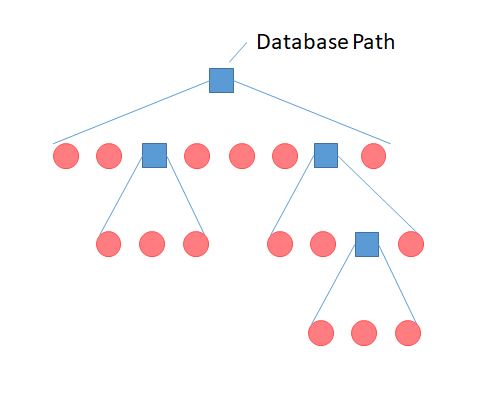
The blue squares are directories, and the red circles are files. The part we easily can solve is to get the red circles from the first level:
private IEnumerable<string> GetFileList(string root, string sourceType)
{
var result = FileSystem.GetFiles(root, sourceType);
}
The remaining sub-problems have the same shape as our original problem:
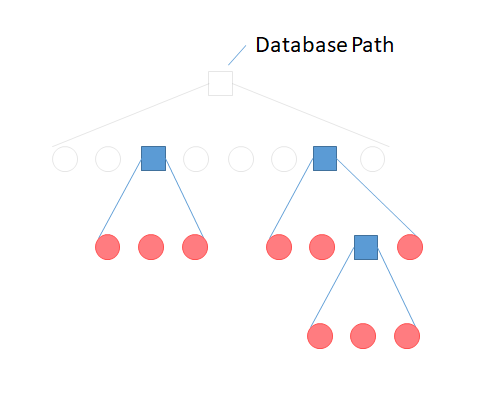
Because the sub-problems have the same shape, we can solve them using the currently written method. We can get the sub-problems – which are sub directories – using the ‘FileSystem.GetDirectories(root)’ call. We can write something like this:
private IEnumerable<string> GetFileList(string root, string sourceType)
{
var result = FileSystem.GetFiles(root, sourceType);
var subdirectories = FileSystem.GetDirectories(root);
foreach (var directory in subdirectories)
{
var subresult = GetFileList(directory, sourceType);
...
}
...
}
This code traverses the whole directory structure, it gets all the file names, but it doesn’t return a full file list. Somehow we need to merge the sub-results. We could create a list and load all sub-results into it, then return it back:
private IEnumerable<string> GetFileList(string root, string sourceType)
{
var result = new List<string>();
var subresult = FileSystem.GetFiles(root, sourceType);
result.AddRange(subresult);
var subdirectories = FileSystem.GetDirectories(root);
foreach (var directory in subdirectories)
{
subresult = GetFileList(directory, sourceType);
result.AddRange(subresult);
}
return result;
}
The drawback of this solution is that it copies lists several times. Not a performance issue in this example, but it is really simple to avoid this. Instead of merging the sub-results, why don’t we pass around a list where every call copies its sub-result into?
private void GetFileList(string root, string sourceType, IList<string> aggregateFileList)
{
var files = FileSystem.GetFiles(root, sourceType);
aggregateFileList.AddRange(files);
var subdirectories = FileSystem.GetDirectories(root);
foreach (var directory in subdirectories)
{
GetFileList(directory, sourceType, aggregateFileList);
}
}
And the original GetFileList() method can start the recursion:
IEnumerable<string> GetFileList()
{
var result = new List<string>();
GetFileList(
this.GetDatabasePath(),
this.GetSelectedSourceType(),
result);
return result;
}
Do we need recursion here?
A directory tree has recursive nature, but we don’t really need to use a self calling method to walk it through. Even if it is not a problem now, self-calling methods have a drawback: they store the state of the problem solving algorithm together with the method call chain. Actually, the current method call chain represents a part of the program solving state.
The problem with this is that we cannot just return to the caller method in the middle of the problem solving with the intention that we continue the process later. Doing this, we lose the state of the problem solving process.
Lets say, that we have a zillion directories to process. The current solution reads this all in a list and then returns it. We need to hold them all in the memory. In the case of zillion directories it would be better to read the files from one directory at a time, process them, then continue with the next directory. Like when we have an iterator which walks through the directory structure as we call the next() method repeatedly. We cannot do this easily when we use self calling methods.
To see that it is quite easy to implement an iterator like that if we use a different approach than recursion, we will write that code in the next part.
