Source code for the test
Data for the test
In this series we are going to solve a programming test which was designed for interviews to see how a candidate can solve practical problems. It is not easy to design a test like this for more reasons. First, it’s hard to tell what makes a good programmer. Smart? Knows a lots of details about popular frameworks and libraries? We can test those things, but unfortunately being very smart and literate in frameworks are not enough. And personally I think the mentioned two are not even that important. We don’t need to solve hard algorithmic problems every day, and frameworks just come and go every second month these days.
What I like to see is a good combination of experience and attitude. How I mean it? I guess we can agree on that a good programmer tries to write good code. And if somebody has been trying to write good code for a longer period of time, then it leaves marks on this person’s programming style. Thus, from someone’s programming style, we can conclude at least a little about their attitude. When we design a programming test, we need to find a way for the candidate to use their own programming style. It means that the code to be written cannot be too short, like a shorter algorithm, we cannot see anything from ten lines of code. But it cannot be long either, because the candidate will try to hurry to finish the test, and might not be using their usual style.
A solution to this contradiction can be if we ask the candidate to improve an existing code. I’ve seen more companies doing this, some of them want a smaller code to be refactored during the interview, others send a homework before the interview, and those source codes are usually bigger.
We will be working on a smaller application which is written the way a beginner or someone who does not really care about code quality would do. The candidate has to add a new feature to the application, and they have two main options. It is possible to add the new feature using the existing structure of the code, which would make it even uglier, showing more obviously that this structure is broken. Or the candidate can spend a little time with refactoring the existing solution, and add the new feature then.
The Application
The application we will be working on is a WPF based application, but we don’t need to know any WPF to solve the test. What the application does is that it reads data-files from a given path, it does some calculation with the data it has just read, then shows the result on the screen.
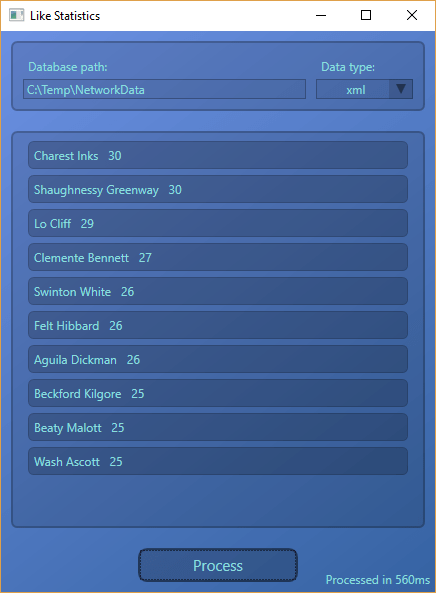
What is the data and what is the calculation?
This is a shortened version of a data file:
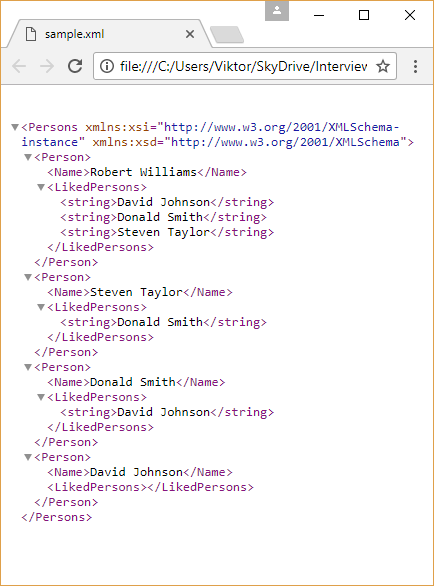
We can see, that it is a list of persons. Every person has a name, and a list with other names. What this file describes is that which person likes which other people. For example, Robert Williams likes David, Donald and Steven. We can draw a graph from this data, showing which person likes whom:
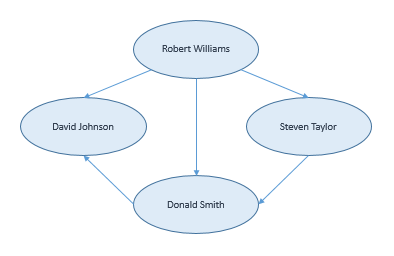
The three arrows starting from Robert Williams’s name show the three people whom he likes. These three arrows are the three lines from the XML file under Robert’s name. We also can see that David Johnson is liked by two other people. We will not find those two arrows directly as a list in the XML file, though. For this information we need to look through the whole XML file searching for David’s name. This is how we can find out that Robert Williams and Donald Smith like David.
What the application calculates is that it takes every person from the database, and counts how many other people like this given person. Then it shows the top 10 most liked people from the database.
The Source Code
The visual studio project is small, and we don’t need to modify most of the files. The important files are those under the “Parsers” folder, and the MainWindow.cs
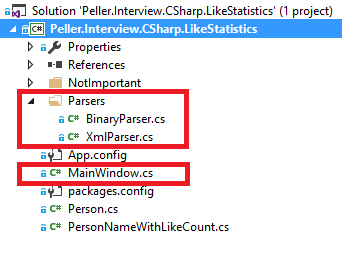
Under the “Parsers” folder there are two parsers. Opening the directory of the data files, we can see that there are files with a third format. This format is the CSV format, but we cannot see any parsers for CSV in the source code. This is because we need to implement one during the test.
Almost every important code is in the MainWindow.cs. It opens the data files from the database, reads all records and calculates the like counts for every person.
The Person class represents a record from the data files. It has a Name and a LikedPersons property, just like we have seen in the sample XML data file. The PersonNameWithLikeCount class is what the application calculates for every Person. It has a Name for the person, and a LikeCount which tells how many other people like the person with the given name. This is the information which will be rendered on the result screen of the application.
We are going to take a closer look to these files later when we solve different problems, but first let’s see what tasks we have as a candidate during the test.
Tasks for the Test
The background story is that we recently took over the maintenance of this application, and the client already has some new requests.
Currently the application supports two formats, a binary and XML format. If we look at the user interface, there is a third option, but it does nothing, the program doesn’t handle it. Opening the database, we can see the CSV files, and we need to modify the code so it will be able to handle them.
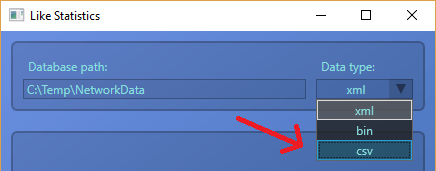
The structure of a CSV file is very simple: every line is a Person record. The first name in the line is the name of the person, the following names are the liked persons.
The second request is about the structure of the database. For every type we can find more files. Also, the database has subdirectories:
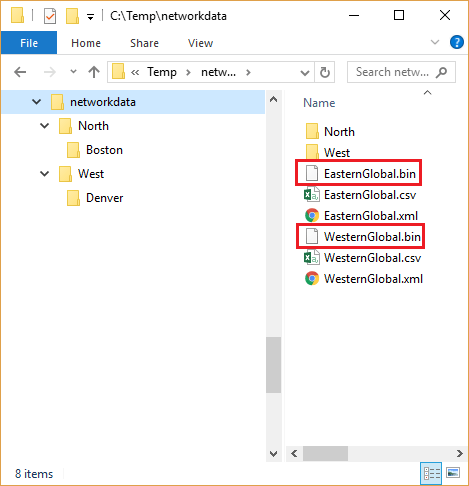
The current implementation supports more files, so in case of binary type, it would read the two marked files. But it wouldn’t take a look into the subdirectories. Because the client needs to process more and more files, they want to organize those file into a tree structure and they requested us to improve the application to process all files from all subdirectories.
The third request is also related to the increasing number of files. The processing time is growing fast with the new added files and we need to find a way to mitigate this.
And the last task of the candidate is to collect the design and implementation problems.
In the next part we will start with the last task, so we look over the code again and name some problems.
