Slow devices
These days microprocessors execute operations at an inconceivable pace. By the time the light of the display reaches the reader’s eyes, a processor executes several operations. The same light would reach the moon a bit more than a second later. Now, it is easier to imagine what an overdone time-lapse video it is for the processor while the hard drive moves its head by a quarter of an inch then waits till the appropriate section of the disk turns under the head with the necessary data. And what an eternity it is for the processor while the user understands the message in the dialog box and presses the ok button? It cannot be pictured.
In fact, the CPU is not forced to wait for these slow events. It would be hard to find a good strategy, anyway. How often the processor is supposed to check for an event? 1000 times in a second? It is too much for a keyboard or a mouse event but maybe it is not enough for a gigabit network. Moreover, usually nothing happens on these devices so checking the devices would be just wasting of the CPU time.
Interrupts
For that reason, CPU does not check devices. Devices tell the processor when data is available for processing. The method of signaling for the processor is called “interrupt“. This name is because when a device signals, then the processor interrupts running its current task, and starts to run a tiny program which was made for that device to prepare the receiving of the data later. The signal of the device is some sort of electronic signal on the processor pins, which triggers a multistep and complicated process which is fortunately needed to be known only by device manufacturers. What we need to know is that short after the interrupt, the data is there and we need to do something with it.
Handling I/O Data
Devices doesn’t send data just to entertain themselves. They send data because some program somewhere expects it. The hard drive provides data because a program requested that data. The network card provides data because a program wants to communicate with a remote system. The mouse sends data because a part of the OS wants to move the cursor accordingly. We can take any example, the situation is the same: when data is available, there is a piece of code to run to do something with the data.
As this is a general need, the Windows operating system provides solutions, not one but more. One solution is – and maybe this is the most trivial one – when a program code requests some data, it also defines the program code which must be started when the data is available (and from the CPU point of view, it might happen only in the very-very far future). How does it work exactly?
Asynchronous Procedure Calls and Completion Routines
The Windows operating system makes it possible to handle devices in asynchronous way. It means that the operation can be started, and it is not necessary to wait its end. For an asynchronous operation it is possible to specify what code must be run when the data is available.
This piece of code is named Completion Routine. The developer can ask for some data from a device, for example by using the ReadFileEx() WinAPI method. This call will not block the execution, it returns almost immediately to the caller, but without the requested data. The developer can specify the address of the program code which he wants to execute when the data is available.
In case of Windows, devices are handled by a module called I/O Manager. When I/O Manager communicates to any kind of device, it treats the communication as reading and writing files. This simplification is not a problem, most device communication means getting or pushing some data, and this is very similar to reading data from or writing data to a file. If it is not about sending/receiving data, I/O manager is able to pass commands to the device, but it is not really important for us right now.
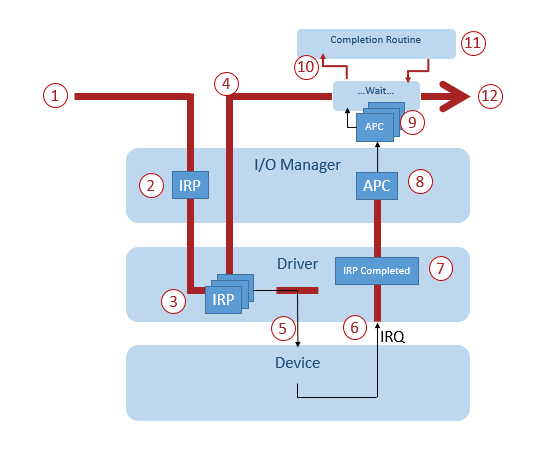
Files (like network connection, serial port, console, etc) must be opened before use. During opening the file, I/O Manager creates a so called File Object in the memory. Read/Write/Other commands will happen on this File Object. The program which opened the file will get a reference number to the created File Object (a File Handle). This reference number can be used to do further operations on the file. These operations are typically done with ReadFile/ReadFileEx/WriteFile/WriteFileEx methods. The implementation of these methods call into the I/O Manager (1). The I/O Manager creates an I/O Request Packet (IRP) which will contain the parameters of the Read/Write operation and the reference to the File Object (2). Then this IRP gets passed to the appropriate device driver. The driver may or may not serve the request immediately. If it can serve immediately, it returns the result back to the I/O Manager. If not, it stores the IRP to be served later and returns back to I/O Manager with the information that the packet is under processing. Now let’s see the path when the driver is not able to give back the result immediately. (3) The I/O Manager gives back the control to the caller (4) so it can do whatever it wants to do. Next time, when the device driver gets some CPU time (because the Operating System scheduled some CPU time slice for it) it starts to process the IRPs from its queue. The order of the processed IRP is decided by the driver; it may depend on some optimization strategy for example. Now the driver sends commands to the hardware device (like network card) and with that, the first half to the IRP processing is done. (5)
After this point it is on the hardware of the device to do some job; the CPU of the computer is not involved. When the device processed the request and it has the data available, then it generates an interrupt on the CPU. The CPU finishes its current task and starts to execute the code of the device driver (6) (it is more complicated in real life, but we do not need those details) The driver gets the data, assigns it to the IRP which requested the data, then signals to the I/O Manager that the IRP is processed. (7)
The I/O Manager checks whether the IRP contains Completion Routine. If yes, it needs to find a way to execute it. The logic behind these Completion Routine is that the thread which started the request must execute the Completion Routine. How will it happen when the whole point of the asynchronous operation was to let the original thread to do other tasks?
Usually we imagine threads as a simple flow which gets the operations sequentially. The reality is that threads are a bit more complex things. Threads can be hijacked to do other operations. The operating system does it regularly in case of an interrupt. In this case it grabs the thread and makes it execute a completely different code.
But there are lighter ways to make the thread to do other operations. Windows operating system has the concept of Asynchronous Procedure Call (APC). Every threads has a queue which can store APC requests. An APC request is basically a subroutine address which must be executed when the thread has time to do that. When does the thread time? When it starts to wait for something. When a thread calls some special WinAPI method in order to wait some events or for some time, the operating system starts to execute the APCs.
So what I/O Manager does is that it pushes the Completion Routine as an APC into the queue of the thread which initiated the operation. (8-9). Now when the thread starts to wait for something (maybe for the data) (10) then the operating system uses this thread to execute the completion routine (11). After the Completion Routine finished, the thread goes back into waiting state and later it may continue its original work (12)
APC Performance Problems
The APC mechanism may work well, but it has some drawbacks, too. If a thread which started the I/O operation has finished, the Completion Routine will not be executed. If the thread which started the I/O operation never goes to waiting state, the Completion Routine will not be executed. For APC, the work of the thread must be designed a way that the thread should stop and wait at some point. This is ideal for threads dealing with GUI, because these threads are waiting a lot for the user do something. But less optimal for server applications. Blocking a thread just to let APCs to run looks resources being wasted. Not wasting when there are APCs to execute. But what if not? In this case it is just a thread with allocated resources which does nothing. If the server has work to do, it needs a new thread. But what if this new thread did an I/O? This thread also must wait, so another thread must be started again. This all can result in excessive thread allocation.
We saw earlier that having too many threads burdens the system even if the threads are just waiting. Completion Routines, thought are intuitive and give good solution in many cases, they are not optimal when it comes to performance. Of course, they can be managed in a way to avoid excessive number of threads, but in this case the usage is not that intuitive. And if we are talking about less intuitive solutions, it is better to take a look at another feature of Windows which was designed for high performance servers – but they also can be used in simpler scenarios.
Completion Ports
This feature is called Completion Port. The Completion Port is what its name suggests: it is a place where the results of asynchronous operations are collected.

The first half of the processing of an asynchronous call is the same as in the case of Completion Routines. The difference starts at (8). In case of Completion Routines, the I/O Manager puts an APC into the queue of the thread which initiated the asynchronous call. In case of Completion Port, the before mentioned File Object must be explicitly assigned to a Completion Port (as more than one Completion Port can exist) After the assignment, whatever thread started the asynchronous operation, the result – like the requested data and the result of the operation) – will be placed to the queue of the Completion Port by the I/O Manager (9). These results are named Completion Packets, and the I/O Manager creates them according to the IRPs (8)
What will process the Completion Packets in the queue of the Completion Port? Completion Ports have dedicated threads assigned to them. The only purpose of these threads is to dequeue and process the Completion Packets. These threads are in waiting state. When a new packet arrives into the Completion Port, one of the threads awakes and processes the packet (10). After processing, it starts to wait again for incoming packets (11). This all is very similar to a thread pool.
So threads are waiting on the Completion Port and start where packets arrives. We talked about that if there are more threads working that the number of the CPU cores, then it may affects negatively the performance. For that reason, it is possible to define an upper limit for Completion Ports, and in this case it doesn’t let to work more threads than the limit. Why does it makes sense to assign say five threads to a Completion Port then define a limit of two? Because a thread processing a Completion Packet can do anything. It can start to wait for an event for example. If a Completion Port started two threads and both of the threads start to wait, no other thread could start to pick up incoming packets if the thread limit is 2. But fortunately, waiting threads doesn’t count. In this case Completion Port will let to start additional assigned thread to pick up packets. Of course, it can happen that the two other waiting thread exit from waiting state and 3 threads will run altogether instead of the allowed 2. So what? Sooner or later these threads will return to the Completion Port waiting for Completion Packets to process, but only at maximum 2 will be allowed to run again to keep the limit.
In case of Completion Ports we don’t have the convenient feature that every asynchronous request can define its own completion function. Moreover, many different File Object can be assigned to the same Completion Port, even with different device type (like network and usb). In this case, all the completion packets will arrive for the same threads and the developer must implement a general program code which is able to dispatch and handle the incoming packets accordingly.
.NET Asynchronous Programming Model (APM)
The .NET Asynchronous Programming Model (APM) is built on Completion Ports. APM provides a quite low level model and it reflects the structure of the operating system. It still helps a lot, most importantly it implements a logic for Completion Port threads which allows the .NET developer to define a custom callback method for every operation – similarly to the Completion Routines. Also, it monitors the number of threads on the Completion Port and assigns new threads if necessary. It gives less chance for a program with bad design to eat up all the threads and get blocked.
We will learn how APM works in the next post.
