In the previous part we refactored the parsers to have a common interface, which made it possible to simplify the big switch block, and then we moved the switch into a factory method. It wasn’t a bad solution, but it can be improved more.
One problem with the refactored parsers is that they deal with two different things. They open the datasource and they parse the data. These are two totally different matter, and the odds are high that they change independently by time. We mentioned an example in the previous episode, that its possible that we need to switch from file to network.
We could say that today we need to read only files, and according to the “YAGNI” principle, we don’t want to prepare for network read. That is a good argument, it would be enough to modify the code, once we need to read from network. But we already have two parsers, soon we will add a new one. So the code which opens the datasource will be included in three different classes. It is called Needless Repetition, and it puts us at the risk of needing to modify our code at different places later. On the top of that, it is a very small change to use a stream in the parsers, so it is not even a lot of work upfront, and it gives a better structure to the program.
If we move out the responsibility of opening the datasource from the parsers, the only thing they do is that they give back Person instances one by one, or I could say that they iterate over person instances. Iterating over something, it may ring a bell, there is a design pattern for this, the Iterator Pattern.
Iterator Pattern
In the Iterator Pattern we have a so called Aggregate, it’s a container of something, like an array of elements, or the records of a database query, but actually it can be and algorithm which provides the digits of pi, so it is possible that we never reach the end of the data. To access these elements, the Aggregate can create an Iterator. The Iterator has a very simple interface, the mostly used method is Next() which returns the next element from the Aggregate.
The .Net framework uses the Iterator Pattern, although with different names, the Aggregate became IEnumerable, and the Iterator became IEnumerator. The interface is also different, in the original pattern the Next() call returned the new element which then was also available through the CurrentItem() call, duplicating a functionality. In .Net, the original IsDone() function moved into the return value of the Next() call – which became MoveNext() – and the “Current Item” is available only through the Current property. I like the .NET version of the pattern a little bit more, I think it is more consistent, but both versions have something I don’t like.
Interface Segregation Principle
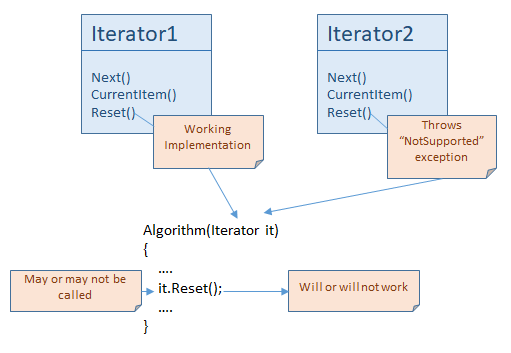
Both versions have a first() or reset() method. It violates the Interface Segregation Principle, because not every iteration or enumeration can be reset. Maybe it is just hard to implement the ‘Reset’, for example when the data comes from a service, and this service doesn’t support it. Or maybe reseting the sequence doesn’t even make sense because of the nature of the data. I can implement the iterator pattern to get the current mouse position for every Next() call, in this case, Reset doesn’t make sense, no such thing that first element, so I it is not possible implement this method.
On the other hand, not every client needs the Reset() method, but they see it. Why is it a problem? Let say that in .NET we have an IEnumerable and an IResettableEnumerable interface, the Resettable version inherits from IEnumerable.
interface IResettableEnumerator<out T> : IEnumerator<T>
{
void Reset();
}
interface IResettableEnumerable<out T> : IEnumerable<T>
{
IResettableEnumerator<T> GetResettableEnumerator();
}
Now if there is an algorithm which wants reset, then it requires an IResettableEnumerable. The code will not compile with IEnumerable.
void AlgoNeedsReset(IResettableEnumerable<string> input) {...}
void Algo(IEnumerable<string> input) {...}
But because we don’t have IResettableEnumerable, these algorithms accept IEnumerable, and if my collection doesn’t support Reset(), because it would have been hard to implement or just doesn’t make sense, then they will throw a NotSupportedException. Or maybe just swallow the reset() call and if the algorithm needs the same sequence after Reset() then it will not work correctly. This is how a bad interface kills the Liskov Substitution Principle.
It also can happen that an algorithm didn’t need Reset() before, but after a modification now it calls it. If we had two separate interfaces, the algorithm would use IResetableEnumerable after the modification, and if the old code passed something with IEnumerable, the code wouldn’t even compile. But because we don’t have, the code will compile, and it may throw an exception runtime. This solution is fragile.
Single Responsibility Principle
But we have an other problem, too, not just that the .Net interface violates the Interface Segregation Principle. Our main motive today is to move out the responsibility of creating the datasource from the parsers, so our classes will not violate the Single Responsibility Principle. But there is a thing which will prevent us to reach or goal, to have Single Responsibility. It wouldn’t be a problem using the Gang of Four interface or the one from .NET 1. The problem came with .net 2.
Between the Aggregate and the Iterator there must be some connection, because the Iterator references things held by the Aggregate. It can be a very simple thing, like a numeric index or memory pointer, so something which is cheap as a resource.
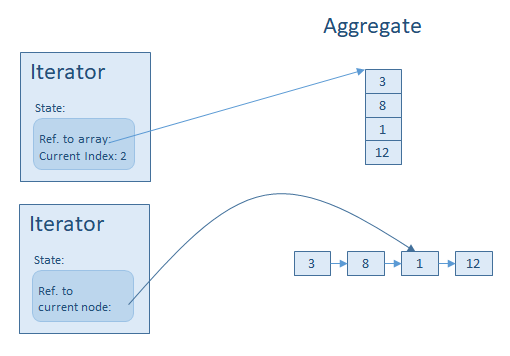
But if the Aggregate is just a proxy, and the real data comes from a database or a remote service, then it can happen, that for the time of the iteration, heavy resource must be allocated, like a network connection.

In this case somehow it must be indicated that the iteration is over, the iterator is not used anymore, so the resource can be freed. There are two ways to do this. First, we could mirror the createIterator() method of the Aggregate, creating a destroyIterator(). The second, that the Iterator gets a finish() or similar method.
To decide which solution is better, we need to take into account the purpose of the Iterator Pattern. First, if we use iterator pattern, the internal structure of the Aggregate is not important anymore. We use the same interface for every kind of collections, independently from its implementation details.
The second purpose is that it unburdens the Aggregate from the maintenance of the state of an iteration. The maintenance of the state is the task of the iterator. If the Aggregate doesn’t care about state of the iteration, probably a destroyIterator() wouldn’t be a good solution, probably most implementation would just forward the call to the iterator, it would call something like iterator.finish(). And if that is the case, we can call iterator.finish() directly. It is probably more convenient for us anyway, because we don’t necessarily have access to the aggregate when we use an iterator.
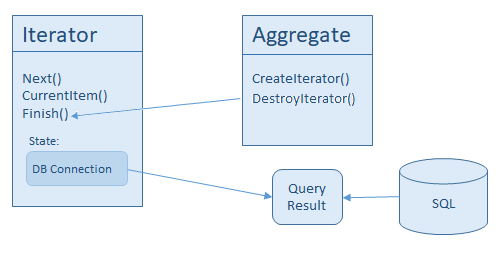
The .NET framework follows this logic, the IEnumerator inherits from IDisposable, so every iterator has a Dispose() method. We can talk about the Interface Segregation Principle again, because most iterators don’t have meaningful Dispose() implementation, probably just an empty method. But the situation here is different to the reset() support.
In case of reset(), we tell every user that they can call it if they want, and the promise is that after the call they get the first element from the collection again. In case of reset() we promise something and maybe we cannot keep that promise.
In case of Dispose() in .Net framework, we mandate every user to call Dispose(). This is the part of the contract. They need to do it every single time, that is the correct use of the iterator. If no implementation? No problem, the call returns without doing anything, but it doesn’t cause any inconsistencies.
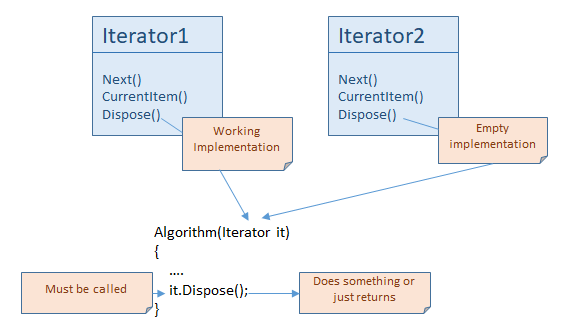
The other option is that only some iterators implement IDisposable, when it makes sense. But the programmer had to check this interface for every iterator, because probably they want the program to be generic, so they needed to write something like this:
void Algo(IEnumerator<string> it)
{
...
var disposableIt = it as IDisposable;
if (disposableIt != null)
{
disposableIt.Dispose();
}
}
Its not really better than when we know that we need to call Dispose anyway, so actually the .NET solution is not bad.
Now we understand that the generic version of the IEnumerator has a Dispose which we need to call. On the other hand, probably most of us never calls it. This is because usually we use iterators with the c# ‘foreach’ loop, and ‘foreach’ understands IEnumerator and calls Dispose() for us.
Refactoring of the parsers
We have two reasons that we have been talking about all of these iterators and the related problems. The first reason is that we want to transform our parsers into iterators, and the second is that we wanted to wash our hands of creating a non-functioning reset(), and because we are moving out the opening of the datasource in the name of Single Responsibility Principle, but in the same time we are bringing in the closing of the datasource, just because the way iterators work under .net. So we will do two ugly things, but none of them is our fault.
The refactor is very simple, the XmlParser looks like this:
internal class XmlParser : IEnumerator<Person>
{
private static readonly string ItemTitle = "Person";
private Stream source;
private XmlReader xmlReader;
private XmlSerializer xmlSerializer;
private Person current;
internal XmlParser(Stream source)
{
this.source = source;
this.xmlReader = XmlReader.Create(this.source);
this.xmlReader.MoveToContent();
this.xmlReader.ReadToDescendant(XmlEnumerator.ItemTitle);
this.xmlSerializer = new XmlSerializer(typeof(Person));
}
public Person Current
{
get
{
return this.current;
}
}
public void Dispose()
{
if (this.xmlReader != null)
{
this.xmlReader.Close();
this.xmlReader = null;
this.source = null;
this.current = null;
}
}
public bool MoveNext()
{
if (this.xmlReader == null)
{
throw new ObjectDisposedException(this.GetType().Name);
}
this.current = this.xmlSerializer.Deserialize(this.xmlReader) as Person;
return this.current != null;
}
public void Reset()
{
throw new NotSupportedException();
}
object System.Collections.IEnumerator.Current
{
get
{
return this.Current;
}
}
}
Changing the BinaryParser is similar. We also need to change ParserFactory, it must use Stream:
internal static class ParserFactory
{
internal static IEnumerator<Person> Create(Stream source, string sourceType)
{
IEnumerator<Person> parser;
switch (sourceType)
{
case "bin": parser = new BinaryParser(source); break;
case "xml": parser = new XmlParser(source); break;
default:
throw new NotSupportedException(
string.Format("Not supported format: {0}", sourceType));
}
return parser;
}
}
The Aggregate
We are missing two additional things. We need to open the datasource somewhere, because the parsers don’t do this anymore, and we don’t have an Aggregate – or Enumerable – from the iterator pattern. It seems that the Aggregate will be the one which opens the datasource. In our case the Aggregate is actually a file, it contains the Person instances, we just need a proxy class which represents this file, and we need a name for this class, lets call it FileBasedDataset. We want to use this class this way:
var dataset = new FileBasedDataset(path, sourceType);
What it needs to do is that it must open the datafile, and according to the sourceType, it must create an appropriate Enumerator – which is a parser in our case. The implementation looks like this:
internal class FileBasedDataset : IEnumerable<Person>
{
private string source;
private string sourceType;
public FileBasedDataset(string source, string sourceType)
{
this.source = source;
this.sourceType = sourceType;
}
public IEnumerator<Person> GetEnumerator()
{
var stream = File.OpenRead(this.source);
return ParserFactory.Create(stream, this.sourceType);
}
IEnumerator IEnumerable.GetEnumerator()
{
return this.GetEnumerator();
}
}
The important method is the GetEnumerator() It’s not complex, but it contains two different things. It opens the datafile and it creates the enumerator. Is it a problem, do we violate the Single Responsibility Principle again?
The only thing we can move out is to open the file, because being the Enumerable, we must create the Enumerator here. We can try to create a more general version based on streams, it looks like this:
internal class StreamBasedDataset : IEnumerable<Person>
{
private Stream stream;
private string sourceType;
internal StreamBasedDataset(Stream stream, string sourceType)
{
this.stream = stream;
this.sourceType = sourceType;
}
public IEnumerator<Person> GetEnumerator()
{
return EnumeratorFactory.Create(this.stream, this.sourceType);
}
...
}
Would it work? Of course not. It has two problems. The first one is that the Enumerators close the stream when they finish, we talked about this and how the Dispose belongs there. If we create an iterator with StreamBasedDataset, and that iterator finishes, it closes the only stream we have, and it is not possible to create new and new iterators. This happens when we don’t handle life time managament in a centralized place.
But even if the iterator didn’t close the stream, this Aggregate wouldn’t be able to create more iterators anyway, because Streams cannot be read from multiple iterators. Streams have only one position, if two iterators start reading it, both move the only position forward.
Back to the FileBasedDataset, we can validate that we open the file here. Our real data lives in files, and the aggregator needs to create the iterator in a way, that it has a state variable which allows it to access the data. In our case the stream represents the state variable, so we need to create the stream (open the file) as a state variable, so can we pass it to the iterator.
Even if someone doesn’t accept this as a valid argument, the new solution is still better then the old one. Even if we had 10 different formats, if we needed to change from file to network, all we would need to do is to create a new Aggregator, like a NetworkBasedDataset, open a NetworkStream there and give it to an iterator. We would not need to modify several parsers to create NetworkStream instead of FileStream.
Using the new classes, let’s see what can we do with that loop which used to be the switch. It wasn’t bad after the first refactor, but because the .NET framework provides extensive support for Iterators, we can simplify the code more:
var filesToProcess = this.GetFileList();
var sourceType = this.GetSelectedSourceType();
var persons = new List<Person>();
foreach (var file in filesToProcess)
{
var dataset = new FileBasedDataset(file, sourceType);
persons.AddRange(dataset);
}
This structure is flexible enough to add the new parser for CSV type, the only thing we need to remember is to add it to the factory class. But before we create the new parser, maybe we can improve the code more, so it will pick up new parsers automatically without adding them one by one to the factory class. This is what we will try to achieve in the next part.
