In this part we are going to take a look at the source code and try to answer the question that usually sounds like “what problems can you see at first look” or “what do you dislike when you look at this code” or “how would you change the code to make it better”.
The keyword here that many interviewers like to hear is “code smell”. I won’t go into what code smell is, because almost everybody knows it, or if not, lots of information is available online. A google search or wikipedia helps to understand the concept.
One file with everything in it
We saw earlier that most of the important code is in the MainWindow.cs. Now, it’s a code smell by itself, a single source file has many important parts – clearly a violation of the Separation of Concerns design principle – another keyword they like to hear on an interview. If somebody doesn’t know the concept, again, wikipedia helps to start.
Even if we do not know WPF, we can understand that this source, this class called MainWindow, is something related to the user interface, it belongs to the presentation, and still the next few lines work something with the file system and DatabasePath, which is something about persistence. Also we can find some calculation in the middle of the source, which is business logic.
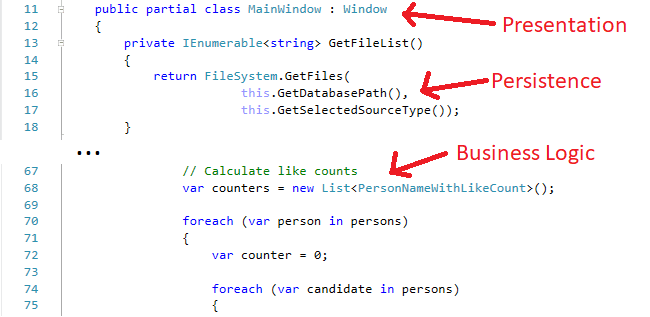 So everything seems to be mixed into a user interface code, and this architectural style actually has a name, it’s called Smart UI. Today Smart UI is considered an anti-pattern – another good word for an interview. Once we tell the interviewer our concerns about the architecture of the application, we can be sure that they will ask back that what other styles we know. So its worth to review some architectural styles, to be able to talk about layers and tiers, clients and servers, and maybe services and message bus-es. A good starting point is this website.
So everything seems to be mixed into a user interface code, and this architectural style actually has a name, it’s called Smart UI. Today Smart UI is considered an anti-pattern – another good word for an interview. Once we tell the interviewer our concerns about the architecture of the application, we can be sure that they will ask back that what other styles we know. So its worth to review some architectural styles, to be able to talk about layers and tiers, clients and servers, and maybe services and message bus-es. A good starting point is this website.
Method order
There is an other problem with GetFileList(). It doesn’t seem to be an important method, at least it doesn’t show much about the purpose of the MainWindow class. Still this is the very first method we can see.
Different developers like to order the methods within a class in a different way, and there is no best way to do this. But in general, the order of the methods should help other developers to understand the purpose of the class. And what helps to understand is the higher level logic that we can call on a class. So it is worth to put the public methods first – these are the methods we can call on a class – and those which implement the higher level logic.
Big methods
The MainWindow class doesn’t have public methods and doesn’t really have higher level logic, almost everything is implemented in a single method. This is an other problem, the button_click() method is too big. Again, different developers have different idea about how long a method should be at maximum, but without any number, we can tell that this method is too big, just because it does too many things.
A sign that this method does too many things is that it has section comments. A section comment is a code smell, it shows the beginning of a new logical block, which could be moved into a separate method:
Another way to find parts to move into separate methods if we look for different abstraction levels.
From the three abstraction levels we can make three methods:
static IEnumerable<PersonNameWithLikeCount>
CalculateLikeCountForEach(IEnumerable<Person> persons)
{
var counts = new List<PersonNameWithLikeCount>();
foreach (var person in persons)
{
var count = CalculateLikeCountFor(person, candidates: persons);
counts.Add(
new PersonNameWithLikeCount()
{
Name = person.Name,
LikeCount = count
});
}
return counts;
}
static int CalculateLikeCountFor(Person person, IEnumerable<Person> candidates)
{
var count = 0;
foreach (var candidate in candidates)
{
if (CandidateLikesPerson(candidate, person))
{
count++;
}
}
return count;
}
static bool CandidateLikesPerson(Person candidate, Person person)
{
return candidate.LikedPersons.Contains(person.Name);
}
It is not always easier to understand a code when it is structured using several small methods. Many developers try to put the little pieces back to its place in their minds. But small methods still have benefits.
Look at the second ‘foreach’ in the original code. If we want to understand what it does, we need to understand every individual line one by one, even if we wanted to understand only the big picture. When it has its own method, and it has a right name, we can see that it “CalculateLikeCountFor” a given person with given candidates. Or look at the ‘if’ statement in the middle of the original method. It is not impossible to understand, but the refactored code has “if (CandidateLikesPerson…”. It looks almost like an English sentence.
A typical problem with big methods is that their logical parts start to get intermingled. The parts start sharing variables, program lines sneak in blocks where they don’t belong to. The figure below shows logical parts with colors, and the structure of a big method:

If we need to change a method like this, sometimes it is hard to predict how a change at the top will affect the rest of the code. Also, if we want to move a block out, like the pink on the figure, it is hard not to break the green code, or bring something unnecessary with pink.
When we have separate small methods, that gives a good boundary to the code, they cannot be intermingled. Also, it is easier to see how the blocks communicate to each other, because we can see it on the method parameters.
It is easier to reuse small methods, and also easier to test them. In the original code, if we want to test if the algorithm calculates the right ‘like count’ for a given person, we need to drive the control through the first ‘foreach’. There are several lines there in which we are not interested but we need to understand how they use the parameters, so by the time the control reaches the second ‘foreach’ it will have the right data to test with. Also, the return value is in a different form than we need. We need only a number, not a list of something, and it makes checking the result of the test harder.
The switch
This is the worst part of the code. The ‘switch’ has two almost identical ‘case’-es. We will fix this part in a separate post.
Magic Numbers
At the end of MainWindow.cs we can see the following:
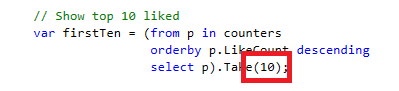
This 10 here is a so called magic number. It is very typical and there are different types of magic numbers. Sometimes we do not know what gives this value. In other cases it is clear what the number means, but the same number is scattered through the code. If we want to modify it, we need to do it on several places. It is easy to miss one, or accidentally modify something with the same value but different meaning. This 10 is the same type, we know that it is ten because we want to see the 10 most liked people on the screen. But if we want to see 15, we don’t know that it is enough to modify the number here, or we need to modify it somewhere else, too.
Catch everything
At the end of the code, we can see an exception handler which catches everything but then does nothing. It may seem a good idea, this hides ugly error messages from the user and prevents crushing the application. On the other hand, what the user expects – finish an operation – will not happen, and no feedback about it. It can be really confusing. Also it is possible that the program gets into an inconsistent state with inconsistent data, and further operations and user actions may cause even more serious trouble.
An important rule of error handling is that we should catch only those errors we can handle somehow. Handling doesn’t mean to solve the problem, usually we cannot solve problems like permission problems or network problems from code. Handling means that we reset the program into a consistent state, we clean things, we roll back half changes, and then let the program run like nothing bad happened. If we cannot ensure a consistent state after an error, we must let the exception bubbling up, maybe a higher level can handle it. Or if not, letting the program die is usually better than letting it run in an inconsistent state, where it may become unpredictable.
Sometimes we catch exceptions even if we cannot handle them, because we want to add more details to the error. For example if the application has no permission to read a file, the Unauthorized Access Exception itself will not help a lot to understand the problem. On a higher level of the code, when we know that what operation was about to execute, we can catch this exception and re-throw a more useful exception.
It is also a problem that the try block includes different operations, and no way that a single exception handler could reset from every possible error. It is not even possible to write a good log entry, because we don’t know what operation caused the problem.
In the next part we are going to eliminate the ‘switch’ block.
